
Web scraping dữ liệu AI bằng proxy: Hướng dẫn chi tiết
Web scraping dữ liệu AI bằng proxy đang là xu hướng tất yếu trong thời đại số. Việc thu thập lượng lớn thông tin đòi hỏi một giải pháp mạng thực sự an toàn và ổn định. Trong bài viết này, ProxyVN sẽ hướng dẫn anh em chi tiết cách thực hiện kỹ thuật này. Hãy cùng khám phá để tối ưu hóa công việc thu thập dữ liệu ngay nhé.
Tổng quan chi tiết về Web scraping dữ liệu AI bằng proxy
Để triển khai thành công một dự án thu thập thông tin, bước đầu tiên là chúng ta cần thấu hiểu bản chất của hệ thống.
Khái niệm cốt lõi anh em cần nắm vững
Trong thế giới công nghệ hiện tại, dữ liệu chính là nguồn nhiên liệu duy nhất để vận hành trí tuệ nhân tạo. Tuy nhiên, việc sao chép thủ công từng đoạn văn bản hay hình ảnh là điều bất khả thi về mặt thời gian và nguồn lực. Kỹ thuật cào dữ liệu tự động đã ra đời để giải quyết bài toán này.

Web scraping dữ liệu AI
Khi anh em thực hiện Web scraping dữ liệu AI, anh em đang triển khai một mạng lưới máy chủ trung gian để thay mặt hệ thống cốt lõi gửi yêu cầu truy cập đến các trang web mục tiêu. Thay vì sử dụng địa chỉ mạng nội bộ của công ty, hệ thống sẽ sử dụng một lớp mặt nạ mạng mới. Kỹ thuật này giúp bảo vệ tuyệt đối danh tính thực sự của máy chủ đang tiến hành thu thập thông tin.
Tại sao trí tuệ nhân tạo khát khao nguồn dữ liệu khổng lồ?
Bất kỳ mô hình học máy hay ngôn ngữ lớn nào cũng cần hàng tỷ điểm dữ liệu khác nhau để tự học hỏi và phân tích ngữ cảnh. Quá trình huấn luyện này đòi hỏi phần mềm phải liên tục quét qua vô số diễn đàn, nền tảng thương mại điện tử và trang tin tức mỗi ngày.
Nếu hệ thống của anh em truy cập trực tiếp mà không có lớp bảo vệ trung gian, các trang web mục tiêu sẽ dễ dàng phát hiện ra lưu lượng truy cập bất thường mang tính chất công nghiệp. Lúc này, họ sẽ ngay lập tức tiến hành chặn đứng địa chỉ mạng của anh em. Chính vì thế, scraping dữ liệu AI bằng proxy là điều kiện bắt buộc để duy trì dòng chảy thông tin xuyên suốt cho các mô hình phân tích dự đoán.
Những rủi ro khi bỏ qua Web scraping dữ liệu AI bằng proxy
Rất nhiều anh em mới bước chân vào lĩnh vực này thường mắc sai lầm khi cho hệ thống chạy cào dữ liệu trực tiếp. Dưới đây là những rào cản kỹ thuật khắt khe mà anh em chắc chắn sẽ gặp phải.
Rào cản từ giới hạn tỷ lệ yêu cầu truy cập
Đây là hệ thống phòng thủ cơ bản nhất của mọi nền tảng website hiện đại. Các quản trị viên luôn thiết lập một ngưỡng truy cập tối đa cho mỗi người dùng trong một khoảng thời gian tính bằng giây hoặc phút.

Giới hạn truy cập
Nếu công cụ AI của anh em gửi hàng chục ngàn yêu cầu liên tục từ một địa chỉ duy nhất, hệ thống tường lửa sẽ đánh giá đây là một cuộc tấn công mạng nhằm làm sập máy chủ. Kết quả là toàn bộ hệ thống thu thập của anh em sẽ bị từ chối phục vụ ngay lập tức. Bằng cách này anh em có thể chia nhỏ và phân tán các yêu cầu này qua hàng vạn máy chủ trung gian khác nhau, giúp vượt qua mọi bộ đếm giới hạn một cách dễ dàng.
Khóa khu vực địa lý khắt khe
Một lượng lớn thông tin giá trị trên toàn cầu được bảo vệ bởi rào cản ranh giới quốc gia. Ví dụ, một cổng thông tin tài chính tại Châu Âu có thể tự động chặn mọi lượt truy cập xuất phát từ khu vực Châu Á. Nếu hệ thống của anh em cần học hỏi từ nguồn kiến thức quốc tế này, địa chỉ mạng nội địa sẽ hoàn toàn vô tác dụng.

Giới hạn truy cập theo quốc gia
Giải pháp Web scraping bằng proxy trao cho anh em quyền năng thay đổi vị trí địa lý của máy chủ chỉ với một cú click chuột. Anh em có thể giả lập thành một người dùng bản địa tại chính quốc gia mục tiêu, đánh lừa hệ thống định vị toàn cầu và tiếp cận nguồn thông tin không giới hạn.
Những lợi ích của Web scraping dữ liệu AI bằng proxy
Việc tích hợp giải pháp mạng trung gian vào hệ thống không chỉ giúp anh em tránh bị chặn mà còn mang lại những ưu thế cạnh tranh vượt bậc trong quá trình phát triển sản phẩm.
-
Tối ưu hóa hiệu suất thu thập: Thay vì bị hệ thống bảo vệ làm gián đoạn liên tục, công cụ cào dữ liệu của anh em sẽ được vận hành với tốc độ cao nhất 24/7. Việc luân chuyển đường truyền liên tục trong quá trình Web scraping giúp tải xuống khối lượng tài liệu khổng lồ trong thời gian cực ngắn, đẩy nhanh tiến độ huấn luyện mô hình học máy.
-
Bảo mật danh tính dự án cốt lõi: Việc để lộ địa chỉ máy chủ đang huấn luyện AI cho các đối thủ cạnh tranh là một rủi ro vô cùng lớn. Áp dụng Web scraping tạo ra một bức tường ẩn danh vững chắc, che giấu hoàn toàn nguồn gốc của doanh nghiệp trước các công cụ theo dõi ngược.
-
Kiểm tra tính chính xác của dữ liệu: Một số nền tảng thường hiển thị nội dung và mức giá khác nhau tùy thuộc vào vị trí của người dùng. Kỹ thuật này giúp hệ thống của anh em thu thập được bức tranh thông tin đa chiều và khách quan nhất.
Lựa chọn loại IP chuẩn xác cho Web scraping dữ liệu AI bằng proxy
Để triển khai hạ tầng mạng hiệu quả, anh em cần phân biệt rõ đặc tính của từng dòng máy chủ trung gian nhằm tối ưu hóa chi phí và tỷ lệ thành công.
Dòng IP từ trung tâm dữ liệu
Đây là loại cơ sở hạ tầng phổ biến và mang lại tốc độ phản hồi nhanh nhất thị trường. Nguồn gốc của chúng xuất phát từ các máy chủ đám mây thương mại cỡ lớn.
IP trung tâm dữ liệu
Ưu điểm tuyệt đối của loại này là tốc độ kết nối cực kỳ cao, rất phù hợp để cào các trang web không trang bị hệ thống chống bot phức tạp. Khi anh em thực hiện Web scraping dữ liệu AI với mạng lưới trung tâm dữ liệu, khối lượng tệp tin văn bản thu về trong một giây là rất lớn.
Tuy nhiên, nhược điểm là chúng có định dạng dải mạng thuộc về doanh nghiệp viễn thông, nên dễ bị các bộ lọc bảo mật nhận diện hơn so với thông thường.
Dòng IP dân cư thực tế
Đây là giải pháp công nghệ cao cấp nhất dành cho các chiến dịch quy mô lớn. Mạng lưới này sử dụng chính những thiết bị mạng thực tế được cấp phát cho hộ gia đình bởi các nhà mạng viễn thông.
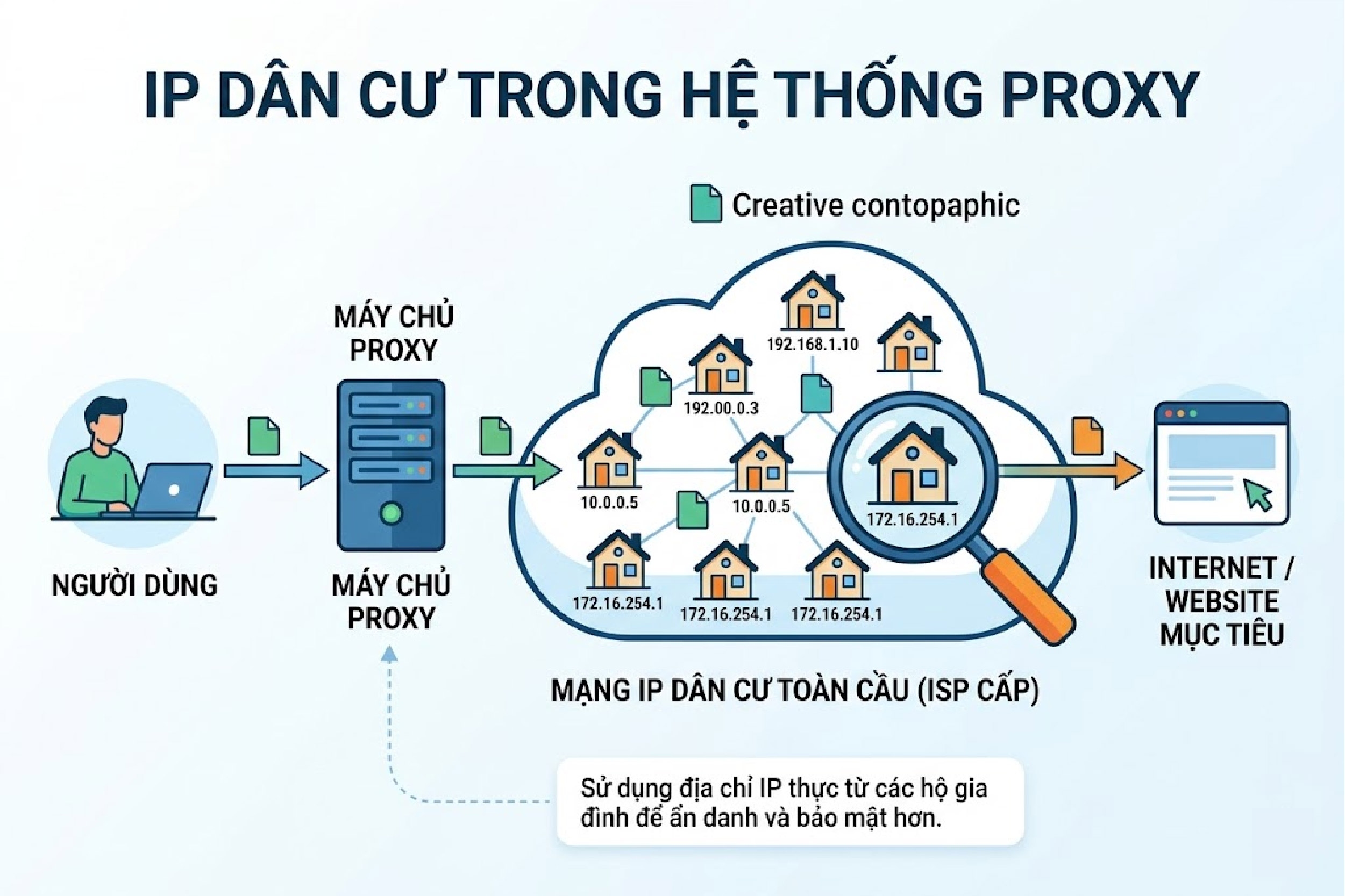
IP Dân cư
Khi anh em áp dụng hạ tầng này, các trang web mục tiêu sẽ phân tích và đánh giá yêu cầu truy cập đó đến từ một người dùng cá nhân hoàn toàn hợp lệ. Chiến dịch Web scraping sử dụng mạng dân cư có tỷ lệ bị chặn gần như bằng không. Nó giúp anh em dễ dàng vượt qua các hàng rào bảo mật trí tuệ nhân tạo khắt khe nhất hiện nay.
Dòng IP tĩnh từ nhà mạng
Loại hình này là sự kết hợp tinh hoa giữa tốc độ của trung tâm dữ liệu và độ uy tín tuyệt đối của mạng lưới dân cư. Chúng được cung cấp trực tiếp từ các nhà cung cấp dịch vụ internet nhưng lại được lưu trữ an toàn trên các máy chủ đám mây chuyên dụng.
Khi anh em cần duy trì một phiên đăng nhập liên tục trong nhiều ngày để lấy luồng dữ liệu chuyên sâu thay đổi theo thời gian thực, đây là sự lựa chọn số một. Anh em có thể tự tin chạy các chu trình dài hạn mà không lo lắng về việc đường truyền bị thay đổi đột ngột giữa chừng.
Chiến lược Web scraping dữ liệu AI bằng proxy hiệu quả
Ngay cả khi đã sở hữu hệ thống hạ tầng tốt nhất, anh em vẫn cần kết hợp với các kỹ năng lập trình khéo léo để đảm bảo phần mềm hoạt động mượt mà.
Kỹ thuật luân chuyển cấu hình mạng liên tục
Anh em tuyệt đối không nên thiết lập một đường truyền cố định cho mọi yêu cầu gửi đi. Việc tập trung quá nhiều lượt truy cập vào một cổng kết nối duy nhất sẽ ngay lập tức kích hoạt hệ thống cảnh báo của website. Thay vào đó, hãy lập trình để phần mềm tự động thay đổi cổng mạng sau mỗi lượt tải trang thành công.
Khi áp dụng triệt để thuật toán luân chuyển vào Web scraping, hệ thống của anh em sẽ trở nên tàng hình trước các bộ lọc truy cập.
Quản lý và giả lập thông số thiết bị người dùng
Các trang web hiện đại không chỉ kiểm tra đường truyền mà còn quét toàn bộ thông số thiết bị của anh em thông qua thẻ User Agent. Nếu anh em gửi hàng vạn yêu cầu chỉ với cùng một thông số mặc định của thư viện lập trình, máy chủ sẽ biết ngay đó là phần mềm tự động.

Giả lập thông số thiết bị người dùng
Anh em cần xây dựng một kho dữ liệu chứa hàng ngàn thông số thiết bị khác nhau để hệ thống tự động thay đổi liên tục, giúp quá trình scraping dữ liệu AI trở nên tự nhiên như người dùng thật.
Giải pháp Web scraping dữ liệu AI bằng proxy từ ProxyVN
Sau khi đã nắm vững toàn bộ kỹ thuật và chiến lược, bước quyết định cuối cùng là tìm kiếm một nền tảng cung cấp hạ tầng mạng thực sự chất lượng. ProxyVN tự hào là người bạn đồng hành vững chắc nhất của anh em trong các dự án khai thác dữ liệu quy mô lớn.
Cam kết mạng lưới hạ tầng vận hành bền bỉ
Sự khác biệt lớn nhất của ProxyVN trên thị trường nằm ở cam kết đảm bảo mạng kết nối luôn ổn định. Chúng tôi hiểu rằng trong ngành công nghiệp huấn luyện trí tuệ nhân tạo, việc rớt mạng giữa chừng sẽ làm hỏng toàn bộ luồng tiến trình phức tạp.
Nhờ việc sở hữu nguồn proxy chất lượng cao và độc quyền, ProxyVN tự tin đảm bảo không bị mất kết nối trong suốt quá trình anh em triển khai các hệ thống cào dữ liệu khổng lồ. Mọi yêu cầu truy xuất của anh em đều được định tuyến thông minh để đạt tốc độ cao nhất.
Hệ sinh thái công cụ hoàn hảo và hỗ trợ tận tâm
Không chỉ dừng lại ở hạ tầng phần cứng mạnh mẽ, ProxyVN còn mang đến một hệ sinh thái phần mềm tương thích hoàn hảo. Chúng tôi cung cấp các tool chất lượng, sử dụng không có lỗi, giúp anh em kỹ sư dễ dàng tích hợp vào bất kỳ mã nguồn máy học nào một cách nhanh chóng.
Hơn thế nữa, trong quá trình vận hành nếu anh em gặp bất kỳ xung đột hệ thống nào, đội ngũ kỹ sư chuyên sâu của ProxyVN sẽ luôn có mặt kịp thời vì chúng tôi có hỗ trợ sửa 24/24. Sự đồng hành tận tâm này sẽ giúp mọi chiến dịch Web scraping của anh em luôn vươn tới sự hoàn mỹ.
Tóm lại, Web scraping dữ liệu AI bằng proxy là kỹ thuật không thể thiếu để phát triển các mô hình trí tuệ nhân tạo. Áp dụng đúng phương pháp giúp anh em tiết kiệm thời gian và chi phí hiệu quả. Nếu anh em tìm kiếm đối tác đáng tin cậy, hãy kết nối với Proxy.vn - Nhà cung cấp dịch vụ proxy chất lượng hàng đầu Việt Nam.



